redis 系列 - 1
一. 什么是 redis
redis 全称 remote dictionary service,即远程字典服务,是一个基于内存且支持持久化的高性能 key-value 数据库。
redis 优点
- 读写速度快
- 支持持久化
- 支持事务
- 数据类型丰富
- 支持主从,读写分离
- 开源
二. redis 支持的数据类型
redis 一共 5 种数据类型:
- 字符串:string
- 散列:hash
- 列表:list
- 集合:set
- 有序集合:zset
string 字符串
string 是最简单的类型,能存储任何形式的字符串,支持字符串,浮点数,整数。
一个字符串类型键允许存储的数据的最大容量为 512 MB。
- 设置值:set key value
- 获取值:get key(字符串回复)
- 删除值:del key
- 自增:incr key(整数回复)
- 自减:decr key
- 按值自增:incrby key value
- 按值自减:decryby key value
- 批量设置:mset key val key1 val1
- 批量获取:mget key key1
使用场景
- 用户 session
- 统计计数器
hash 散列
hash 可以存储多个键值对之间的映射,可以方便的对同类数据进行归类整合存储。
值的类型同字符串,也可以进行自增操作。
- 设置值:hset user:1 name wu
- 获取值:hget user:1 age
- 按值自增:hincrbr user:1 age 2
- 获取所有:hgetall user:1
- 批量获取:hmget user:1 name age
- 批量设置:hmset user:2 name xu age 18
- 删除一个:hdel user:1 age
- 删除全部:del user
- 字段是否存在:hexists user:1 name
- 不存在则设值:hsetnx user:1 lock(并发锁)
- 只取字段名:hkeys key
- 只取value:hvals key
- 数据长度:hlen key
使用场景:
- 购物车
1 | hset cart:1001 10091 1 // 用户 1001 添加商品 10091 1件 |
set 集合
字符串的无序集合,每个字符串都是唯一的。可以方便的对数据进行交集、并集、差集等操作。
- 设置值:sadd key value,values…
- 获取所有元素:smembers key
- 移除元素:srem key value,values…
- 是否在集合:sismember key value
- 集合差:sdiff key
- 交集:sinter key
- 并集:sunion key
- 数据个数:scard key
- 随机获取:srandmember key
- 随机弹出:spop key
使用场景:
- 好友/关注/粉丝/感兴趣的人集合
- 随机展示数据
- 黑白名单
- 文章标签
1 | sadd post:1:tags php redis |
list 列表
列表类型可以存储一个有序的字符串列表,常用的操作是向列表两端添加元素,活着获得列表的某一个片段。
列表内部是使用双向链表实现的,所以向列表两端添加元素的时间复杂度为 O(1),这意味着即使是千万数据,获取头部或尾部的 10 条记录和从 20 条数据取出 10 条记录的速度是一样的。
但是通过索引访问元素会比较慢。
- 添加数据:lpush key value values…,rpush key value values…
- 取出数据:lpop key,rpop key
- 获取片段:lrange key start stop,lrange key -2 -1 // -1 表示最右边一个,-2 表示右边第二个
- 数据长度:llen key
- 删除前 count 个指定值元素:lrem key count value
- 获取指定索引:lindex key index
- 索引赋值:lset key index value
- 只保留片段:ltrim key start stop
- 插入元素:linsert key BEFORE|AFTER pivot emelemt
使用场景:
- 文章存储
- 队列
- 新鲜事、日志等很少访问中间元素的应用
zset 有序集合
有序集合类型是使用散列表和跳跃表实现的,所以即使读取位于中间部分的数据速度也很快。但是有序集合笔列表类型更耗费内存。
- 添加数据:zadd fraction 90 wu
- 获取数据:zscore fraction wu
- 修改数据:zadd fraction 99 wu
- 倒序取出:zrange fraction 0 3
- 正序取出:zrevrange fraction 0 3
- 取出范围:zrangebyscore fraction 80 100 // 不包括100 (100
- 增加:zincrby fraction 2 wu
- 获取元素个数:zcard fraction
- 指定范围内的元素个数:zcount fraction 80 100
- 移除元素:zrem fraction wu
- 按范围移除元素:zremrangebyrank fraction 80 100
使用场景:
- 排行榜
- 跳表数据结构
基础命令
所有键名:keys *
是否存在:exists key
获取类型:type key
单个删除:del key
全部清空:flushall
字符长度:strlen key
追加 value:append key value
三. 相关知识
缓存穿透:是指查询了一个不存在的数据,缓存层不会命中,存储层也不会命中,导致每次查询都要去请求存储层,失去了缓存保护后端存储的意义。解决:存储层不命中以后,仍将空值缓存,但是设置一个较短的过期时间。
缓存击穿:热点 Key,大量并发读请求引起的小雪崩, 就是缓存在某个时间点过期的时候,恰好在这个时间点对这个 Key 有大量的并发请求过来,这些请求发现缓存过期一般都会从后端 DB 加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端 DB 压垮。解决:根据热点 key 设置永不过期;并发锁。
缓存雪崩:缓存设置同一过期时间,引发的大量的读取数据库操作。解决:分散过期时间,设置过期时间时加上一个随机数字;设置永不过期,数据库更新时同步缓存。
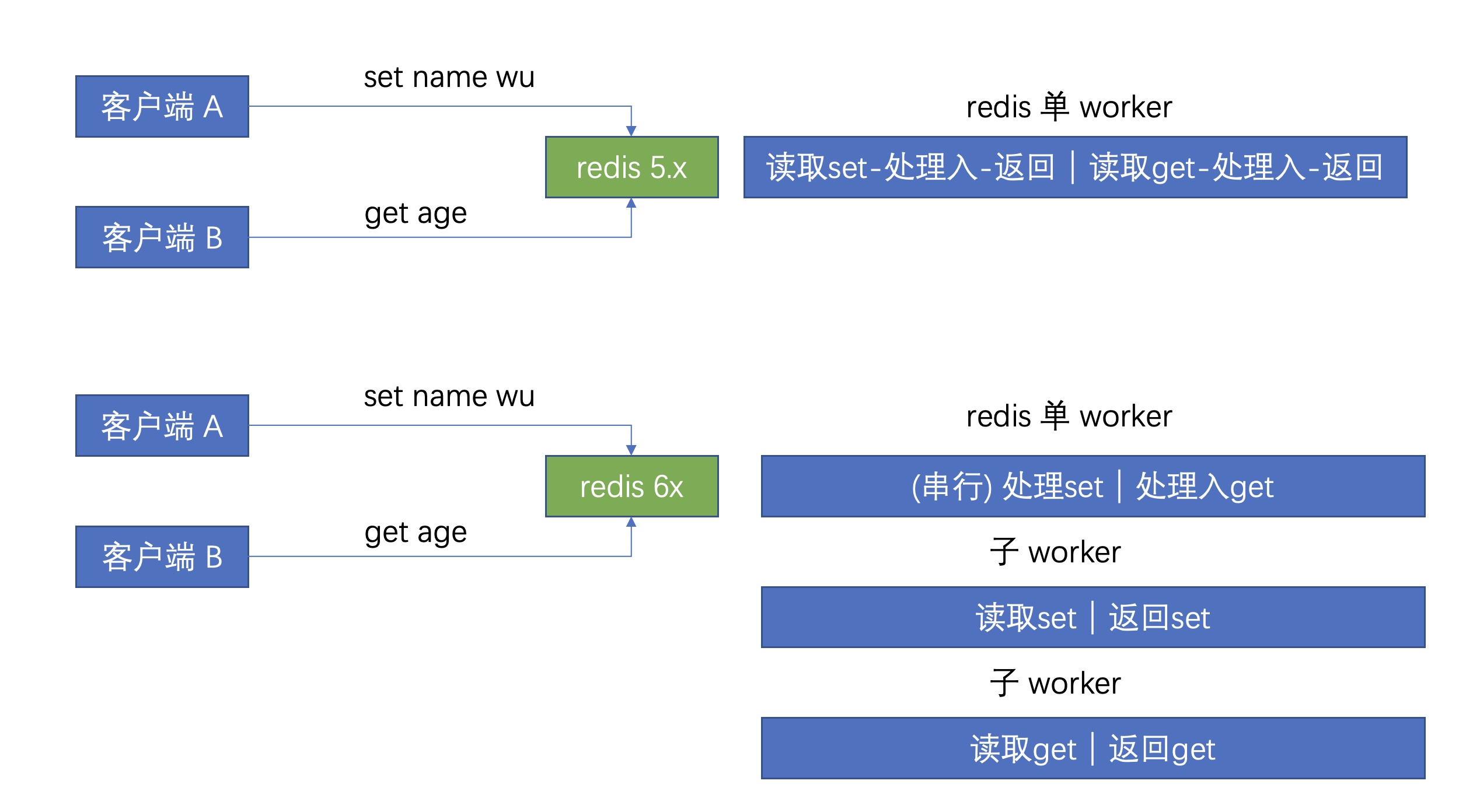
是单线程还是多线程
首先,不管说 redis 是单线程还是多线程都是不对的,因为要从不同的方面考虑。
5.x 以前是单线程,但是这个单线程并不是说 redis 本身只有一个线程,而是说它在业务处理时是单线程的。
6.x 以后,redis 在业务处理时,读取命令和处理命令分别由不同的线程处理,串行变成了并行,性能得到提升。